Concept of Large Financial Models
December 17, 2025
Subscribe to the Effie Labs NewsletterI'm exploring the concept of what I call a Large Financial Model (LFM), a specialized AI system built to master a single financial instrument by learning its unique patterns, behaviors, constraints, and "personality".
The core bet is simple: instead of training one model across many tickers and hoping generalization wins, you train one dedicated model on one ticker (or one instrument family) and make it ridiculously competent at that one thing.
Why single-instrument specialization is the point
Real trading behavior is not just "price goes up/down". Each instrument has its own microstructure, participant mix, options market depth, headline sensitivity, and recurring event rhythms (earnings, guidance updates, macro correlations, index flows, options expiries).
The LFM idea is to treat an instrument like a domain: learn its regimes, its predictable reactions, its "typical" and "atypical" vol patterns, and how its options surface re-prices around specific catalysts.
What the model should learn
The goal is not "predict tomorrow's close". The goal is an internal representation of the instrument that is useful for:
- forecasting distributions (returns, volatility, tail risk), not single points
- understanding regime shifts (calm, trending, mean-reverting, crisis)
- modeling options market repricing (IV surface moves, skew changes)
- mapping catalysts to market response (earnings, guidance, headlines, macro prints)
- producing actionable outputs with uncertainty + constraints
A clean mental model
LFM is closer to "a dedicated market analyst for one ticker" than "a price predictor". It should be able to say what regime we're in, what's historically similar, what the options market is implying, and what scenarios look plausible.
Data sources and schema (the boring part that makes or breaks it)
The dataset should be multi-modal and time-aligned. If alignment is sloppy, you get lookahead, leakage, and fake skill.
1) Underlying price & volume (OHLCV)
Baseline daily (and ideally intraday) bars: open, high, low, close, volume. You can extend this with corporate actions (splits, dividends), trading halts, session boundaries, and extended hours.
2) Options chain + surface
This is where LFMs get interesting. You want full chains over time: strikes, expirations, bid/ask, mid, volume, open interest, IV, and Greeks. The surface (IV vs strike vs expiry) is basically a living compression of market expectations.
From raw chains you can derive features like: ATM IV, term structure, skew, kurtosis proxies, IV change around events, and "pinning" behavior near round strikes into expiry.
3) News, filings, earnings, and sentiment signals
News is messy. But even without perfect NLP, you can extract useful structured events: timestamp, source, category, polarity estimate, and whether it's an earnings headline vs rumor vs macro.
Everything must be timestamped as the market would have seen it. If you label an earnings surprise using numbers published after the close, your features must not include that information before it becomes public.
Feature engineering (useful, but don't let it become a crutch)
You can let the model learn raw patterns, but engineered features still help with stability, interpretability, and faster learning. The key is to compute them without leakage and to shift them correctly.
| Bucket | Examples | Why it matters |
|---|---|---|
| Returns & trend | log returns, rolling momentum, moving averages, breakout levels | captures drift vs mean reversion regimes |
| Volatility | realized vol, range-based vol, vol-of-vol, gap stats | helps align with IV and risk regimes |
| Market microstructure | spread proxies, volume spikes, session effects, VWAP distance | captures liquidity and participation shifts |
| Options surface | ATM IV, skew slope, term structure, IV change around catalysts | encodes market expectations and tail pricing |
| Event signals | earnings calendar, news embeddings, surprise proxies (post-event only) | connects catalysts to response patterns |
Model architecture: what an LFM could look like
I'm intentionally not locking into one architecture. The LFM label is about the product and training philosophy, not one specific neural net.
Here's a concrete example of what an LFM architecture could look like, using AAPL as the target instrument:
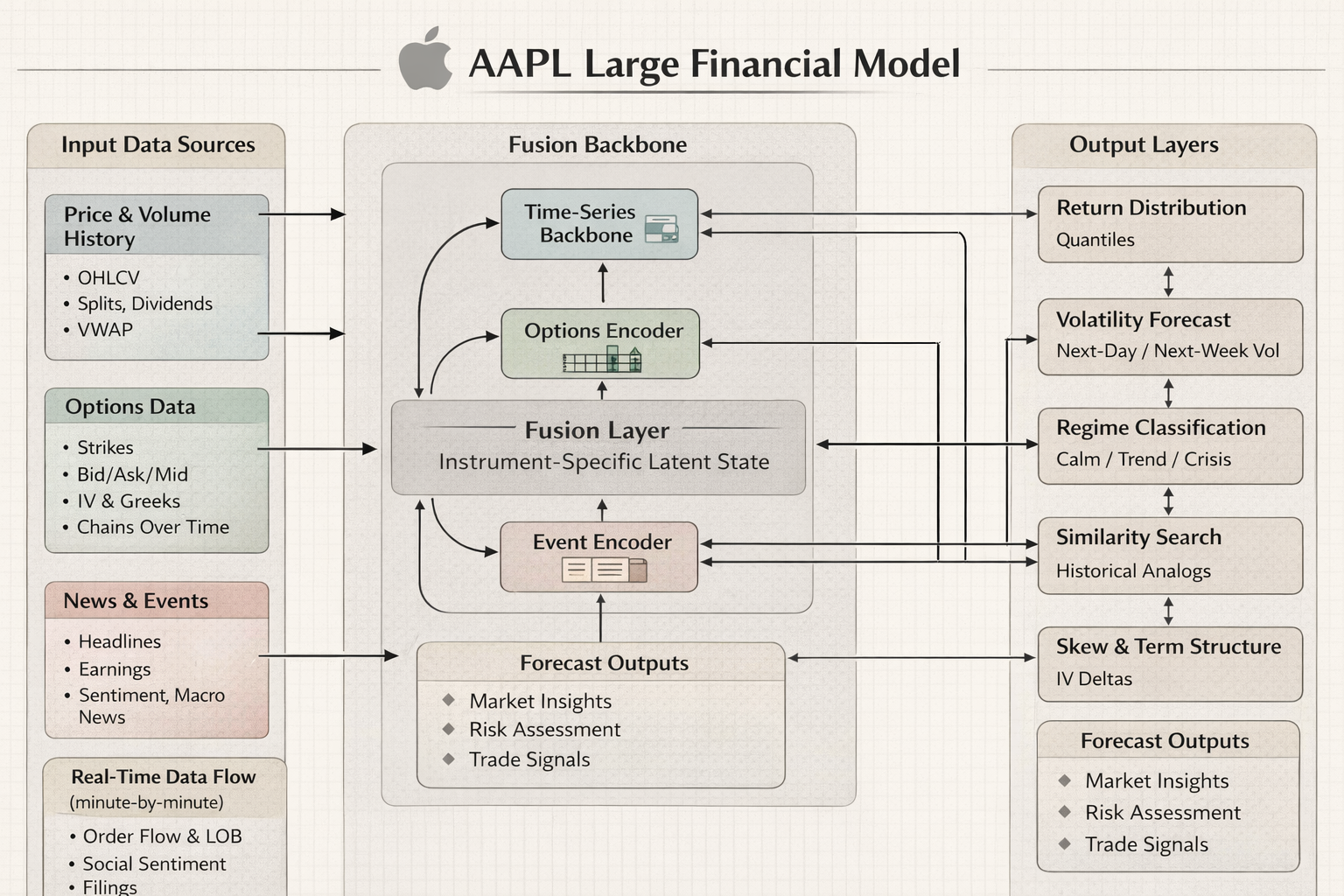
The core output of an LFM is identifying the optimal options contract to buy at any given moment. Rather than producing complex distributions and narratives, the model evaluates the entire options chain—every available strike and expiration—and selects the single contract that offers the best risk-adjusted opportunity based on current market conditions, implied volatility, Greeks, liquidity, and the instrument's historical patterns. The system uses mathematical comparison across all available contracts to rank and select the optimal option, updating this recommendation minute-by-minute as market conditions evolve.
Real-time operation: minute-by-minute data flow
In production, an LFM operates on a continuous ingestion cycle. Every minute, the system ingests fresh data across multiple modalities: option chains with full strike and expiry coverage, option Greeks (delta, gamma, theta, vega, rho) computed from the current surface, news feeds and filings, social media sentiment signals, live trade prints, and order book snapshots (bid/ask depth, spread dynamics, and liquidity layers).
Before any of this reaches the model, substantial preprocessing code structures the raw feeds into a unified, time-aligned representation. This includes validating timestamps, normalizing contract identifiers, filtering stale quotes, reconciling Greeks across different pricing models, aggregating order book levels into meaningful features, aligning news timestamps with market events, and ensuring no lookahead leakage. The goal is to transform heterogeneous, noisy streams into clean, structured inputs that the LFM can reliably process.
This preprocessing layer is critical: garbage in means garbage out, and the model's performance depends on having the best cleaned data possible. The minute-by-minute cadence ensures the LFM stays current with market state while maintaining strict temporal boundaries for evaluation and inference.
Similar prior work
The LFM concept synthesizes ideas from several research directions. Here are examples of related work that cover parts of this stack:
Options surface modeling / learning from IV surfaces
- "Deep Smoothing of the Implied Volatility Surface" (NeurIPS 2020) — neural approach to fit/predict IV surfaces
- "A Neural Network Approach to Understanding Implied Volatility Surfaces" (Cao, 2019) — uses neural nets to model how IV changes with return/moneyness/maturity
- "Deep Learning from Implied Volatility Surfaces" (Kelly et al., 2023) — treats IV surfaces like images and extracts predictive information
- "Deep Learning Option Pricing with Market Implied Volatility Surfaces" (2025) — builds pricing from arbitrage-free surfaces (S&P 500 options 2018–2023)
Microstructure + order book "single-instrument-ish" modeling
- "DeepLOB: Deep Convolutional Neural Networks for Limit Order Books" (Zhang et al., 2018) — deep model for price movement prediction from LOB data
Multimodal finance (price + news + other modalities)
- "FinMultiTime" (2025) — large-scale dataset aligning news + tables + charts + prices across US/China, explicitly about temporal alignment of modalities
- "MAGNN" (2022) — multimodality graph neural network for financial time-series prediction (price + text etc.)
- "Guided Attention Multimodal Multitask Financial Forecasting" (ACL 2022) — explicitly addresses combining global/local multimodal information for forecasting tasks
- "FinZero" (2025) — multimodal pre-trained model for financial time series reasoning/prediction on a financial dataset
These works cover parts of the LFM stack (options surface learning, microstructure DL, multimodal alignment). The LFM framing is essentially a product/system-level synthesis of these ideas, but focused per-instrument.
Disclaimer
This is research and engineering exploration, not financial advice. Any mention of strategies or outputs is about evaluation methodology, not a recommendation to trade.